|
Clio develop
The XRP Ledger API server.
|
|
Clio develop
The XRP Ledger API server.
|
A single Clio node has one or more ETL sources specified in the config file. Clio subscribes to the ledgers stream of each of the ETL sources. The stream sends a message whenever a new ledger is validated.
Upon receiving a message on the stream, Clio fetches the data associated with the newly validated ledger from one of the ETL sources. The fetch is performed via a gRPC request called GetLedger. This request returns the ledger header, transactions and metadata blobs, and every ledger object added/modified/deleted as part of this ledger. The ETL subsystem then writes all of this data to the databases, and moves on to the next ledger.
If the database is not empty, clio will first come up in a "soft" read-only mode. In read-only mode, the server does not perform ETL and simply publishes new ledgers as they are written to the database. If the database is not updated within a certain time period (currently hard coded at 20 seconds), clio will begin the ETL process and start writing to the database. The database will report an error when trying to write a record with a key that already exists. ETL uses this error to determine that another process is writing to the database, and subsequently falls back to a soft read-only mode. clio can also operate in strict read-only mode, in which case they will never write to the database.
To efficiently reduce database load and improve RPC performance, we maintain a ledger cache in memory. The cache stores all entities of the latest ledger as a map of index to object, and is updated whenever a new ledger is validated.
The successor table stores each ledger's object indexes as a Linked List.
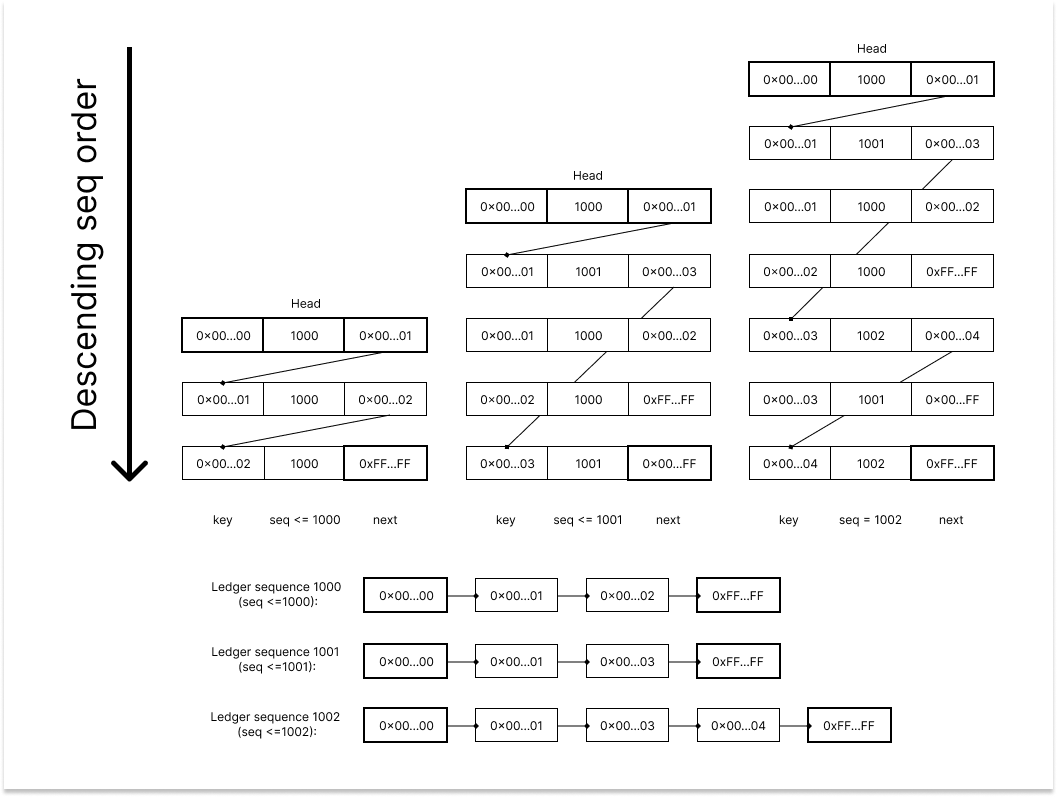
The Linked List is used by the cache loader to load all ledger objects belonging to the latest ledger to memory concurrently. The head of the Linked List is data::firstKey(0x0000000000000000000000000000000000000000000000000000000000000000), and the tail is data::lastKey(0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF).
The Linked List is partitioned into multiple segments by cursors and each segment will be picked by a coroutine to load. There are total cache.num_markers coroutines to load the ledger objects concurrently. A coroutine will pick a segment from a queue and load it with the step of cache.page_fetch_size until the queue is empty.
For example, if segment 0x08581464C55B0B2C8C4FA27FA8DE0ED695D3BE019E7BE0969C925F868FE27A51-0x08A67682E62229DA4D597D308C8F028ECF47962D5068A78802E22B258DC25D22 is assigned to a coroutine, the coroutine will load the ledger objects from index 0x08581464C55B0B2C8C4FA27FA8DE0ED695D3BE019E7BE0969C925F868FE27A51 to 0x08A67682E62229DA4D597D308C8F028ECF47962D5068A78802E22B258DC25D22. The coroutine will continuously request cache.page_fetch_size objects from the database until it reaches the end of the segment. After the coroutine finishes loading this segment, it will fetch the next segment in the queue and repeat.
Because of the nature of the Linked List, the cursors are crucial to balancing the workload of each coroutine. There are 3 types of cursor generation that can be used:
cache.num_diffs number of ledgers. The default value is 32. In mainnet, this type works well because the network is fairly busy and the number of changed objects in each ledger is relatively stable. Thus, we are able to get enough cursors after removing the deleted objects on mainnet. For other networks, like the devnet, the number of changed objects in each ledger is not stable. When the network is silent, one coroutine may load a large number of objects while the other coroutines are idle. Below is a comparison of the number of cursors and loading time on devnet: | Cursors | Loading time /seconds |
| ------- | --------------------- |
| 11 | 2072 |
| 33 | 983 |
| 120 | 953 |
| 200 | 843 |
| 250 | 816 |
| 500 | 792 |
cache.num_cursors_from_diff cursors. This type is the evolved version of cache.num_diffs. It removes the network busyness factor and only considers the number of cursors. The cache loading can be well tuned by this configuration.account_tx table until there are cache.num_cursors_from_account cursors.